How I Used AI to Build A Blog Into My App
Revealing the secret sauce that makes Codex actually reliable

Most people hand their AI coding agent a task and hope for the best.
Codex goes off, does a bunch of things, and you get back something that’s either close to right or quietly broken in three places you won’t notice until production.
There’s a better way. This is the same process I used to get JobsLobster ready to add a blog with AI.
Here is what I actually did, along with the repeatable method I now use for every significant feature we add.
Start With a Skill Book, Not a Prompt
At Elephant Stripes, the consulting company I run, we call it a phased implementation plan. You can also think of it as a skill book for your agent.
The idea is simple. Before you write any code, you capture everything the agent needs to do good work.
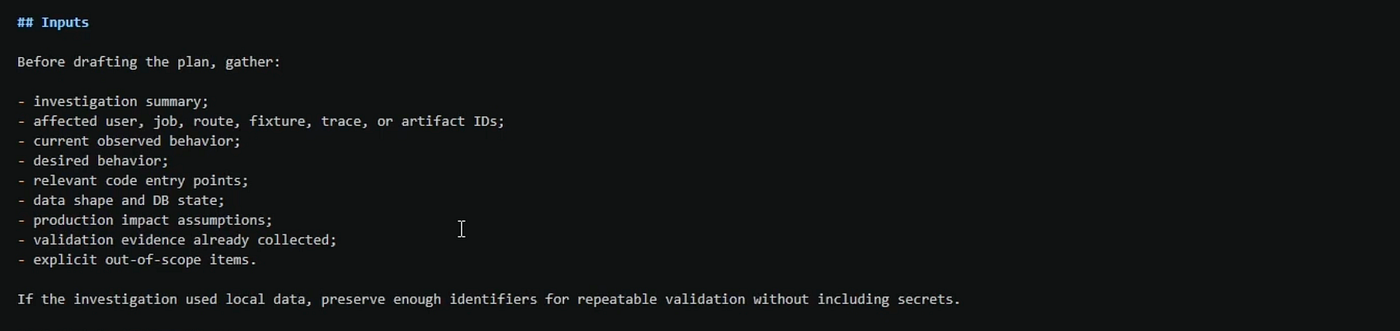
That investigation document covers:
Investigation summary
Affected user flows, jobs, route, fixtures, traces, or artifacts ID,
Current observed behaviour
Desired behaviour
Relevant code entry points
Data shape and DB state
Production impacts
validation evidence, and
What’s explicitly out of scope
You end up with two states clearly defined: where you are, and where you want to be. The gap between them is the work.
The skill book gives the agent examples of how you’ve done similar work before, your code shape preferences, and the product decisions already made. It eliminates a whole class of guessing.
The Per-Phase Operating Loop
Once the skill book is ready, you build the implementation plan.
For this project, that meant seven phases covering SEO foundations, JSON-LD, robots, sitemaps, metadata, and, finally, a production push.
Each phase follows the same loop:
Complete the phase work
Update the plan document with what was done
Document production impacts (migrations, environment variables, any changes needed in OpenClaw)
Validate and smoke test
Write a changelog entry into changelog.md
Commit and push the branch
Move to the next phase only if there are no blockers
That loop is important. It means every phase has its own record when it’s done. Production impacts get captured as you go, not reconstructed at the end. The changelog writes itself. You can push to production with confidence because every phase told you exactly what changed.
What JobsLobster Actually Looked Like Before the Fix
I want to be honest about the state the app was in, because it’s probably not far from where a lot of fast-built apps end up.
The audit found:
No robots.txt and no sitemap.xml
Pages that should be noindex were being indexed
Only a default top-level JSON-LD blob, nothing route-specific
Every public page falls back to the same global SEO title and description

That’s a real app with real users. None of those issues was catastrophic. All of them were quietly holding back organic growth.
The benchmark I used was the Elephant Stripes site. It has route-specific JSON-LD, proper metadata, solid page speed scores, clean Search Console access, and automatic AVIF conversion on image upload. That’s the standard. The goal was to bring JobsLobster up to that level before building anything content-heavy on top of it.
Handing It to Codex
Once the plan was ready, I opened a fresh Codex thread. New thread, clean context window.
The prompt told Codex to:
Work in the correct branch
Read the README, the implementation plan, and the phased deployment documents
Start with Phase 1 only
Follow the per-phase operating loop
Keep JSON-LD in sync automatically when admin fields change
Keep SEO controls and previews inline on the admin pages that own the content

Then I let it run.
It worked through all seven phases. There are still a few things to tighten up. Image conversion to AVIF needs more attention. Some pricing data was pulled in from the wrong source. A couple of fields still need manual content.
But the foundation is solid. Robots.txt and sitemap exist. Metadata is no longer duplicated across every page. JSON-LD is route-specific. The Search Console and Page Speed APIs are wired up correctly.
When the blog goes in, it lands on a foundation that’s actually ready for it.
Why This Process Works
The phased implementation plan does a few things that a single-shot prompt can’t.
It gives the agent a bounded scope for each phase. There’s no ambiguity about what Phase 1 is and isn’t. The acceptance checks either pass or they don’t. The agent updates the document as it goes, so you always have a record of what was done and what’s still pending.
It also keeps the context window clean. I started a new thread in Codex specifically because the context from planning and investigation would have muddied the build. Fresh thread, focused instructions, phased scope.
That’s the whole system. Investigate thoroughly, define current and desired state, wrap it in examples and a per-phase loop, hand it over with clean context.
It’s repeatable. It produces consistent results. And it gives you documentation as a byproduct rather than a separate task.
The Blog Comes Next
The whole point of this exercise was to get to a place where a blog would actually do something useful. The plan is simple: as JobsLobster adds new features, those features get announced on the blog and emailed to signed-up users. Content that is useful because the SEO underneath it is properly structured from day one.
That’s the next step. And now the foundations are there to do it properly.

If you want to watch the full process play out in real time, including where Codex hits snags and how the per-phase loop handles them, go and watch the YouTube video. It’s the uncut session, just over an hour. Worth seeing if you’re planning to use this approach yourself!
JobsLobster is an AI resume-builder that helps you tailor your resume to specific job descriptions. Try it for free at jobslobster.com.